
Data is not information, neither is data architecture the same as information architecture, despite the two terms often being used interchangeably. The situation is not helped by TOGAF 9.1 which, while it defines data architecture, has practically nothing to say on the subject of information architecture.
Things are even further confused by the term ‘information architecture’ being used within the web development industry to exclusively refer to the way in which web content is structured.
In this post I’d like to go some way to sketching out what an information architecture is concerned with, its value, and how we might construct such an architecture.
Let’s start by defining information as: data + context. Data without context is meaningless. For example, take a column of floating point values in a database table – while a developer might be able to discern something about the meaning of the values by physically inspecting the database table and column names – the values are meaningless to the naive user until they are presented on a computer’s screen in a field labelled “Cholesterol level (mg/dL):”
This distinction between data and information is captured by the concept of the information asset.
Information assets (and not data assets or data objects) are the subject of information architecture. An information asset is defined as the combination of one or more data sources managed and communicated by a system. The system via its presentation layer is responsible to manage the context in which the data is presented to communicate the correct intended meaning. A ‘system’ may be implemented using paper-based, manually maintained or electronic technologies.
An information asset, like other assets has value and a life-cycle. The value of an information asset varies over its life-cycle and is dependent on the quality of the underlying data, as well as, characteristics of the system that manages it (e.g., system responsiveness, accessibility). The discipline of information management is typically how the information asset life-cycle is managed.
Information assets are categorised (non-exhaustively) at a conceptual level as:
- Ontologies
- Terminologies
- Taxonomies
- Catalogues
- Schedules
- Documents
- Templates
- Dashboards
These high level categories are used to further group information asset logical types needed within an enterprise in order to successfully conduct its business (e.g., budget reports, strategic plans, performance dashboards, financial statements, project reports, medical records, trade blotters, organisational charts, job schedules, calendars etc).
Each logical type has a life-cycle and can be implemented physically using current or future state data sources and systems. Moreover, different underlying technologies are more suited for different information asset categories (e.g., dimensional vs relational database design, OWL vs XML, or spreadsheet vs data visualisation tool), and so an information architecture begins to scope out the type of technologies and systems required.
Future state implementations aim to improve the value of an information asset by reducing overall implementation cost, or improving information accuracy, security, quality or timeliness of information presentation. For example, a future state information architecture might identify an information asset (e.g., a performance dashboard) that today is implemented using a manually maintained spreadsheet, to be implemented in future as a SharePoint based dashboard automatically populated with data from a data warehouse or a number of external data sources in near real time.
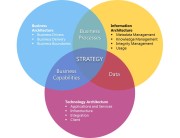
Information architecture provides the means to view and categorise the information required to support and enable business processes. By understanding its alignment with process we can begin to identify the value of the information and how critical it is to a business. In this way information architecture provides a means to scope and prioritise activities like master data management, application portfolio management, and data warehousing.
How data are physically structured and managed is the business of data architecture and the discipline of data management. The physical structuring of data should be transparent to the information architecture as it is typically mediated by the application layer. For example, a single data warehouse is likely to store and manage the data that appear in multiple information assets.
Common benefits of developing an information architecture include consolidation of reports and improved reporting consistency. It is not uncommon for the same logical type of information asset (e.g., monthly project status report) to be implemented across an organisation using various configurations of systems and data. An information architecture highlights these opportunities for business improvement.
Information architecture is an often misunderstood, and overlooked architectural domain that logically sits between the business and application domains. It provides a crucial link between business process and, the applications and data used by an organisation.
By identifying the information assets necessary to conduct business, and how these are structured, information architecture scopes the requirements for current and future data technologies while abstracting away the complexities of application design and data management.
With the current popularity of Big Data, and increasing data storage and cost, the need to understand the value of information derived from this data is as important as ever.
The simple acquisition of more data, much like the acquisition of more technology no longer represents a competitive advantage in itself. Rather, it is the deliberate, intelligent and targeted use of data and technology that is likely to lead to disruptive information driven market opportunities.
Information architecture provides the view to identify the business value of information and the means to achieve a more targeted approach to the use and management of both data and technology within the enterprise.



































































You present some wonderful “information” here very clearly. I had already completely bought into the information asset concept, and have had a lot of success using it to improve our overall enterprise understanding.
What I think is the master stroke here, is to hone in on the aspects of the current information asset, which an enterprise could and should improve.
There’s probably a paper of its own to expand upon things that make an ideal information asset. Some are obvious, some may not be. Off the top of my head, my future information architecture would promote improvements around information asset cost, timeliness, trust, market competitiveness, uniqueness, insightfulness, depth of knowledge and usefulness/applicability, discovery and pace of learnability, ability to be “mashed up” into new information. Actually the list may never end.
As you state, data & information techniques and environments are continually becoming more complicated or complex. “The right information at the right time to the right person in the right format” no longer really cuts it for the modern information architect.
Whereas, a tell-tale distinction in the data-information debate is, if we’re just managing data alone, the problems involved in its management are significantly simpler. Complexity only comes from the difficulty in understanding, capturing, maintaining, and presenting data with its intended context.
Good article, I like the differentiation between the two. I guess, traditionally we have thought mostly about structured data but with the advent of social media and explosion of unstructured & Big Data, it gets more complicated.
Chris,
I find the distinctions you have made very interesting and would like to follow them up with you, given a mutually acceptable time. I’ll connect via LinkedIn if that’s OK with you.
Best regards,
Geoff
The problem I have with this post is that stipulating definitions to construct a hard difference between data and information introduces an arbitrary complexity and so unnecessarily complicates the discussion.
Every sensible definition that can be applied to information, may be correctly applied to data. Yes there are social conventions – but they are not as normalised as you assume. In the production of information in business processing data is characterised as ‘raw’ or ‘simple’ and information as ‘complex’ and ‘processed’. But in science and research information is characterised as preceding data – which is information that has been structured for analysis. Or to borrow your term context. In fact in mathematics, physics, cognitive science, neurology and analytic philosophy you most certainly have information without context. If you add context all you get is more information.
The weird underlying assumption of the awful Data – Information – Knowledge – Wisdom (DIKW) model, seems to be that the psychosocial complexity of interpretation somehow imparts a different kind of being to the thing being interpreted. I have never seen an argument for this model that wasn’t naive stipulation and description.
– Information is difference.
– The context within which information can be interpreted, is also information.
– Information only has value when it’s used.
– Information can be encoded.
– The same information can exist in multiple formats and locations.
All of these assertions are as true of ‘data’ as they are of ‘information’.
If you filter out differences that can stand, what is left is differences in formats, uses, and technologies – all of which are useful and completely agnostic to either the density of information, or the complexity of the interpretation task.
This post has a makes a lot of good observations about the challenges of managing information.
The stipulation of the data/information dichotomy just adds cognitive plaque to the text.
http://vimeo.com/3248432
Hi Ric
Thanks for your thought provoking comments. The distinction the post makes is between ‘raw’ data and information. Complexity is not a criteria for distinguishing information from ‘raw’ data, neither is the degree of processing that may have given rise to the ‘raw’ data or information.
Regarding the assertions you’ve listed, it is correct that most can be applied equally to data and information. However, if you mean by the first assertion that information represents or communicates difference and that this assertion also equally applies to raw data then I think I’d respectfully disagree. Without context it is impossible to tell whether two pieces of raw data represent difference or whether the data are in fact equivalent but in a different format/encoding. Regarding the second assertion that the context in which information is presented is itself information, when applied to data serves to reinforce the point of the original post – that data is not information. When data is presented in a context then it is informative. I would suggest that raw data presented in a ‘context’ that only consists of additional raw data, remains uninformative.
As for the Wisdom/Knowledge/Information/Data model this is a discussion for another day – the original post dealt only with the distinction between information and data.
Thanks Chris. This is the best description and explanation of Information Architecture I have read. Having worked as an information architect over the past 10 years, I have had to educate employers and peers alike on the differences between Information and Data/Content. Your blog articulates these differences and the importance of IA beautifully.
Chris, love your work. Would enjoy a followup on MIKE 2.0 and DMBOK related to the distinctions raised above.
Re the TOGAF terminology issue, my personal theory is that this was caused by the desire not to confuse the Information Systems Architectures *phase*, with the architecture *domain* related to Information and Data within it – with a variety of negative knock-on impacts, including a stronger focus on data than information. But it’s just a hunch and I haven’t validated.